Wish You Were Here: Context-Aware Human Generation
https://arxiv.org/abs/2005.10663

This pipeline allows you to harmoniously add a person to your photo. It consists of three parts: generation of a mask where a person should be inserted; transformation of the inserted person into a given pose; additional face correction. The complexity of the task is that it is necessary not to generate the whole picture, but to harmoniously fit into the already existing one. In contrast to deep fakes, there are more degrees of freedom here. Also this article has a cute title.
The input is the original picture with several people and the picture with the individual person to be added to the original picture. Also, optionally, a bundling box is provided, where to insert a person.
The first model is Essence generation network (EGN) - by the input segmentation mask of the original picture it generates a mask for the person to be inserted. The first channel of the input tensor - segmentation of all people, different values are encoded different parts of the body/clothes, the second channel - segmentation of facial parts (binary), the third (optional) - target bundling box. Architecture - pix2pixHD with adversarial loss, feature matching loss by discriminator (but without VGG feature matching). Also regularization into gradients by input segmentation to reduce high-frequency patterns in the generated mask.
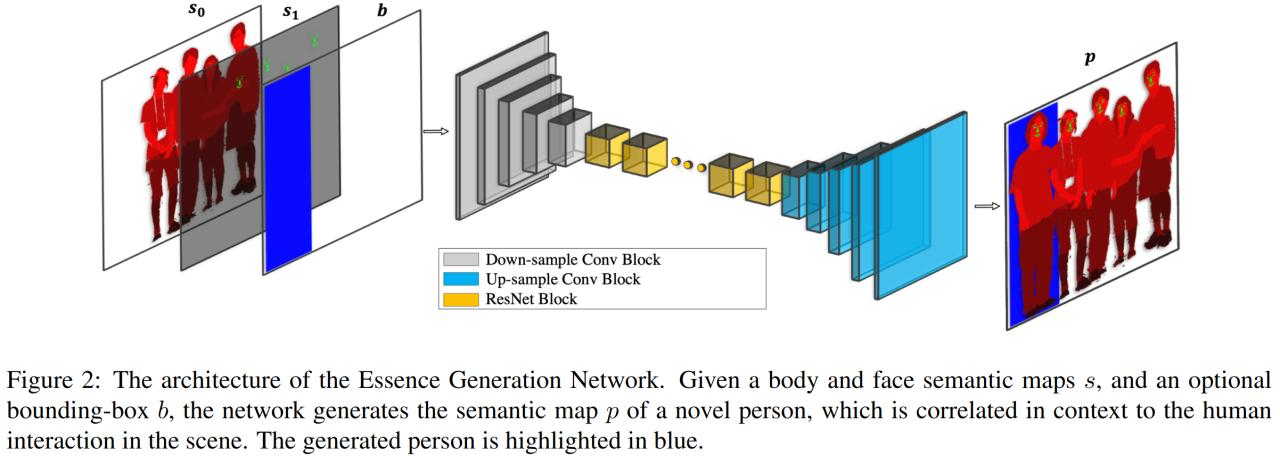

Example of data for the first model
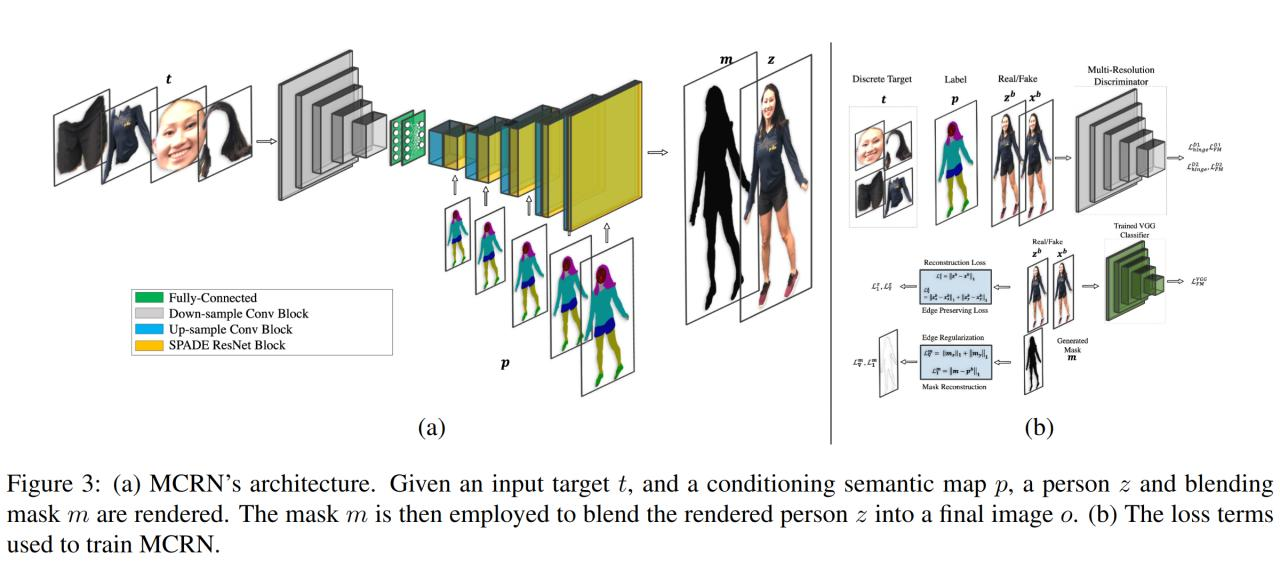
The second model Multi-conditioning rendering network (MCRN) - generates a person in a given pose (512x512). Separate parts of the human (selected by another pre-trained segmentation model) concatenated by channels are fed to the encoder. Decoder - SPADE, in which the tensor from the encoder is fed, as well as the mask of the target position obtained from the previous network. At the output, there is a generated body Z and a new precise mask for it M. The final picture (with body glued) O is obtained after applying mask M to Z and gluing it into the original picture.
Adversarial hinge loss, feature matching loss, and L1 between Z and target body X (but only on area B, which is an optional bundling box). The output mask is forced to be similar to the original pose mask by L1 loss (but it could be different). Also, the "smoothness" regulator is added on the mask. On the final image - VGG feature matching loss between target image.
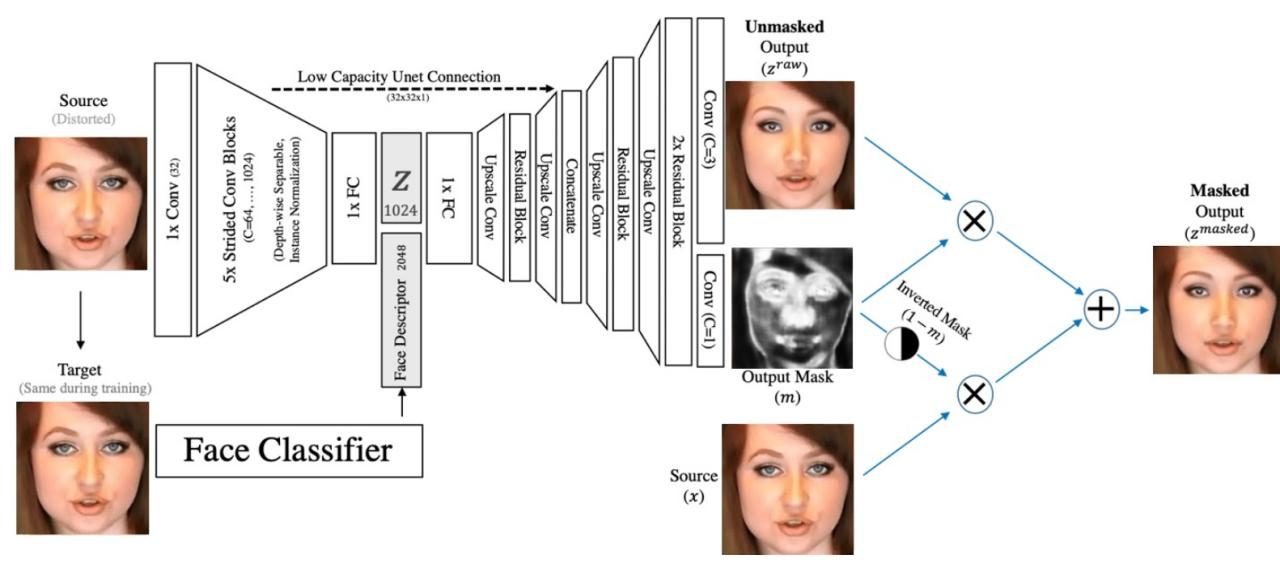
Third Face refinement network (FRN) - improves the face. Crop generated in the previous step of the face O is taken to the input, as well as an embedding (VGGFace2) of the original face of the person before the transformation. They concatenate VGG embedding to the bottleneck after the encoder. The output has an improved face and mask for blending with the original face. Loss - perceptual by the VGGFace model. Architecture has taken from their previous work, image from there.
For the dataset, they use Multi-Human Parsing (DeepFashion is too artificial, plus they need a lot of people on one picture). For EGN model training, one person was randomly removed (to be predicted). Bundling box B was sampled at one level by height +-10%, and randomly across the entire width.
MCRN was trained on each person from the train part of the dataset individually - it turns out they were trained on a person in the original position to predict him in the same position. But in order to model simply could not throw the information, they divided the parts of the person into separate channels and resized (so the part of a body completely occupied the channel on width and height), and the bottleneck is narrow enough (256).


My favorite picture from the article, looks really creepy and funny how a model tries to add a mask of a man to a picture.
Many different experiments to show that their method works under different conditions, for example, they tried to draw the mask by hand and the second network still coped and generated the realistic bodies. The dressing also works (replacing several body parts from another person). They invented their own numerical metrics and also performed user-study. Also cool ablation study with different losses.
Another interesting point - when removing the masks of people from the dataset, they always took the person who is behind someone in the case of the crossing. As I understood, if it were the other way around, the model would be too easy to understand where to add a person (it would be visible cut out the contour on the remaining person).
They themselves mention disadvantages - now the generation of segmentation for a person doesn't condition on the person, who should be generated. For example, the model does not know that we want to add a girl with long hair and therefore will not generate a hair mask.