Few-Shot Adversarial Learning of Realistic Neural Talking Head Models

Paper from Moscow Samsung AI Center about heads animation from ICCV19. Basically, for the models that allow you to make high-quality animation of the face, you need to retrain the model for a specific person. The approach of the authors allows you to animate a new face from several photos. They use meta-learning(training on different people) and before the inference on a new person do fine-tuning.
An alternative to training a large model for each person may be to use warping of the original face (such as First Order Motion Model). This requires only one picture, but there are problems with new angles and hidden parts of the face. They also mention methods that use statistical modeling of the head, but there are problems with rendering everything near the face or hair. For their approach, they were inspired by the similar few-shot text2speech pipeline.

In the meta-learning phase they use M different videos (in each individual person), where for each X_t face there are landmarks turned into a schematic image of the Y_t face as in the diagram above. The pipeline consists of 3 models:
- Embedder - takes a pair(face and landmarks), gives out embedding, which should contain information about the person, but not about the specific pose of the face.
- Generator - takes a landmarks image and facial embedding (obtained on other images from the same video), produces a generated face corresponding to these landmarks. The embedding goes through the frozen MLP (this is an important point) and is fed to the generator through the AdaIN (only in the decoder part of the generator).
- Discriminator - takes the face, the corresponding landmarks, and the video index. At first, the convolution encoder outputs vectors of the same size as Embedder. Next is a scalar product of this vector and a row from matrix W corresponding to the index of the current video (projection discriminator idea). The output contains one number - realism score. The discriminator takes into account not only the correspondence of a face to landmarks but also the correspondence of a face to a specific person.
Actually, the realism score in the discriminator is a bit more complicated. There are also components that do not depend on the video index (w_0 and b). They are responsible for the overall realism of the face-landmarks.
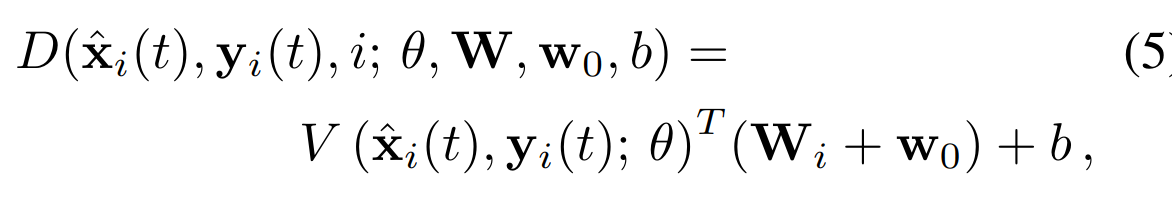
During the meta-learning part they sampled the video, from which they selected a frame to be reconstructed. They sampled 8 more frames, fed them to Embedder and averaged the embeddings. VoxCeleb1 dataset for comparison with baselines(1 FPS), VoxCeleb2 for final model(25 FPS). Minimized the following loses between generated and real face:
- content perceptual loss on VGG features
- adversarial hinge loss
- feature matching loss by discriminator
- the matching loss between Embedder embedding and vector in the discriminator (in table W) which is important for fine-tuning.
After meta-learning, you can already use the model by feeding a few photos of a new person into Embedder. But it is possible to improve the preservation of identity if you fine-tune it:
- the new person's embedding is fed via MLP to the generator, and if at the previous stage this MLP was frozen, now it is unfrozen and fine-tuned together with the whole generator.
- The discriminator is also needed for fine-tuning, but since there is no vector in the W matrix for a new person, it must be taken from somewhere. This is where the matching loss which made the Embedder e_i embedding value similar to the vectors in the discriminator W_i comes in place, so the embedding can replace the vector in the discriminator (w' = e_i + w_0).

During fine-tuning only content loss and adversarial loss are minimized. On the GPU it takes up to 5 minutes.
For stability, they added spectral normalization and several self-attention blocks to the models.

Compared with baselines too in a few-shot mode (1, 8, 32 frames for a new person). They also compared to their approach without matching loss and fine-tuning (without this loss the fine-tuning will not work) - FF(feed-forward). By numerical metrics, they lose to the baselines, but by user-study, they win, which is usually more important in principle.

The result of 0.33 of their best model of 32 photos per user-study - very cool, out of 3 photos with one generated user can not identify the real ones.

The drawbacks of their method are that landmarks do not encode the gaze. Also when using landmarks from one person to another, it is immediately noticeable. From the person to himself all normal. It is necessary to have a landmark adaptation.
