MonkeyNet: Animating Arbitrary Objects via Deep Motion Transfer
https://arxiv.org/abs/1812.08861
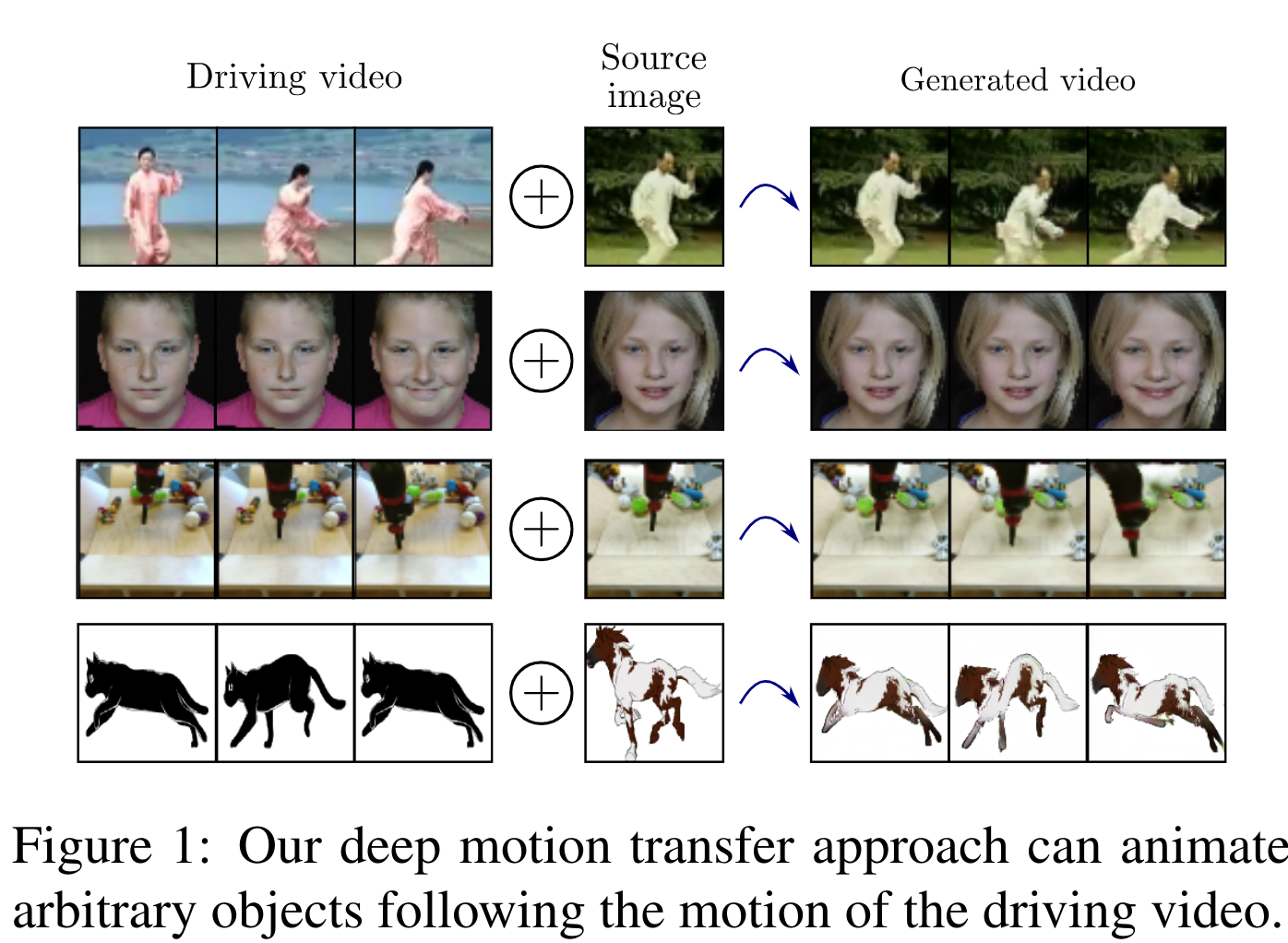
The predecessor of the First Order Motion from the same author. It animates the object in the image based on another video. They learn their own keypoints, predict the optical flow from the source keypoints to target keypoints, and use it to generate a new image. The main idea is to separate Motion and Appearance. MonkeyNet because of MOviNg KEYpoints.
Their pipeline consists of three networks Keypoint Detector, Dense Motion prediction, and Motion Transfer network. Everything learns end2end, only different videos without any labels are needed for training.
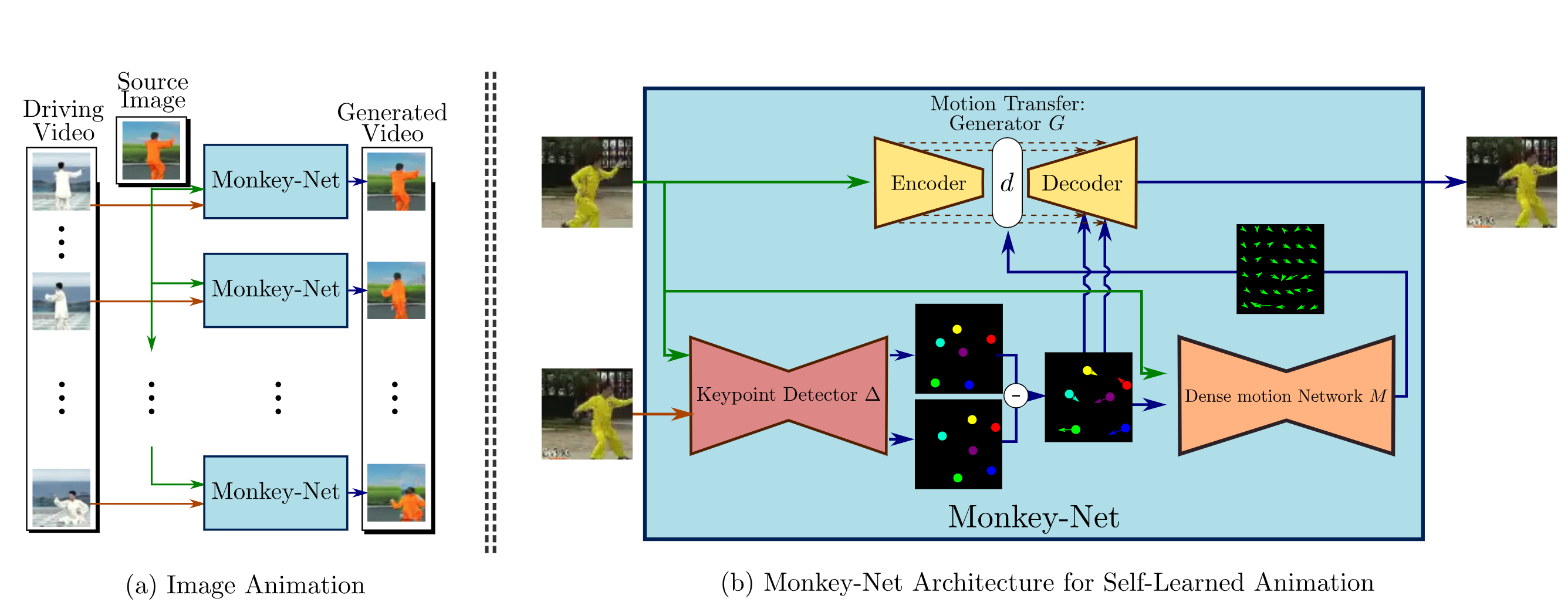
Keypoint Detector (∆) is a UNet (like all networks below), which predicts the heatmaps of the keypoints, each keypoint is a separate output channel with softmax (with temperature to sharpen the distribution). Next for each channel, they fit a Gaussian with its mean and covariance matrix and in the end they draw that Gaussian on each channel as a heatmap. This is necessary as a regularizer so that there is one keypoint per channel, and the covariance additionally gives the "direction" of the keypoint (for example, for the leg). Further, the difference between such tensors from the source and target images is mostly used.
Dense Motion prediction (M) - they make the assumption that each keypoint found above is on a locally non-deformable (rigid) part of the object, so it must move in one piece. So for each keypoint they predict the mask of the part of the object belonging to the M_k keypoint. It also predicts a separate mask for the background (just another one). Next, the shift of respective keypoints (the uppermost tensor on the 3rd image) is calculated - for each of them they find the difference between it on target picture and it on the source picture - the difference exactly between the coordinates (Gaussian centers). The received vector of a direction for each keypoint is stretched (duplicate values) on all height and width of the initial image, multiplied by a predicted mask of the corresponding keypoint, and then aggregate results for all keypoints. This results in a coarse optical flow for the individual parts on one image. In addition to the masks, a residual flow is immediately predicted for the entire image, which models the shift for "flexible" objects. The resulting optical flow is simply the sum of coarse and residual.
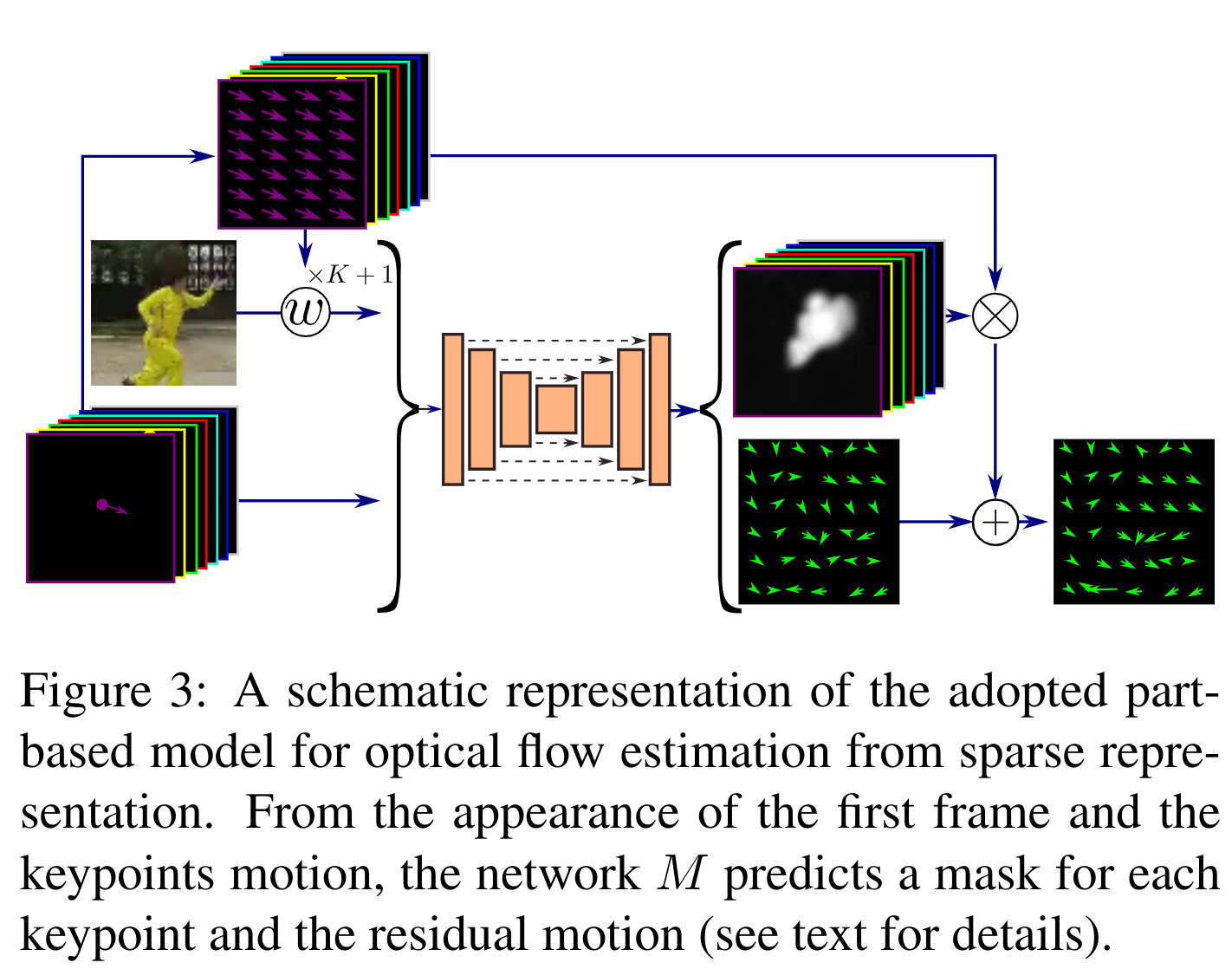
The UNet input, which predicts the masks M for the keypoints and the residual flow, feeds the difference between the source keypoints' Gaussians and the target, as well as the source image. But the source image is fed in a tricky way. In order to better match the original image and the local area where the keypoint is moving on the target image, they duplicate the original image for each keypoint and move each according to the keypoint displacement vector (an upper tensor of image 3). All shifted images are concatenated channel-wise with the Gaussian differences. It turns out in different channels there will be different shifted pictures, which locally match with the corresponding keypoints in the target picture.
Motion Transfer network (G) - takes all that to generate a target from the source. This is UNet, but since it is not capable of generating large changes in geometry by default, so the authors used the optical flow. All encoder outputs (skip connections) are warped with the optical flow, before concatenation in the decoder. Also, the differences of Gaussian keypoints are additionally concatenated to each of such skip connections. This is necessary so that gradients can flow into Keypoint Detector directly, not through Dense Motion (because of end2end).
The loss for the final, generated with G image, is LSGAN. The discriminator takes the concatenation of the generated (or real) image and the differences in Gaussian keypoints. The second loss is a feature matching by the discriminator (not VGG perceptual so it doesn't rely on the domain).
For inference, they map the absolute coordinates of the source object into relative coordinates with respect to the target coordinates. Therefore, the object must be on the first frame in the same position as the object in the reference video. This is a serious limitation, but the relativity of the coordinates solves the problems when the source keypoints and target keypoints are very different (for example, when the target person has big cheeks - picture 5, second column).

They beat everybody on the metrics (by the time of 18th year):



At the end of a cool ablation study, there are many other results, such as visualization of learned keypoints.
