Training Generative Adversarial Networks with Limited Data

https://arxiv.org/abs/2006.06676
Work by StyleGAN authors, allowing the use of GANs when there are little images. The main idea is a tricky use of differentiable augmentations, without modifying loses or architecture. Adding it to StyleGAN2 showed comparable results with an order of magnitude fewer images (several thousand).
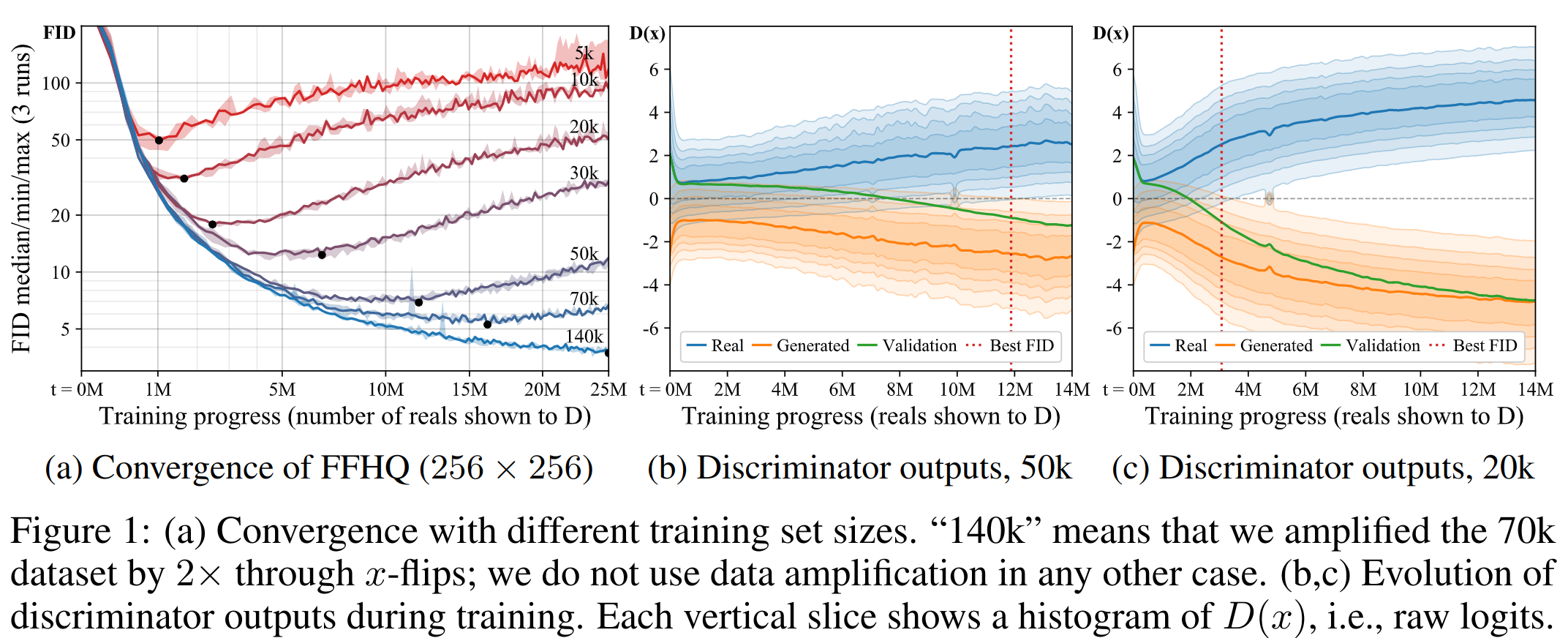
The problem with the small dataset is that the discriminator quickly overfit. On a large dataset, this is not a problem (as authors of BigGAN said - the role of D to pass the signal, not generalize). You can see in the figure below how the data volume affects training (the smaller the data the worse the FID). Comparing (b) and (c) we can see that on a smaller volume, the distribution of D (discriminator) outputs very quickly stops intersecting for real and fake, and the distribution on validation data becomes close to fake - overfitting.
Simple augmentations on the original dataset is not suitable for image generation, because then these augmentations "leak" and the generator starts to generate images with these augmentations. Proposed earlier Consistency regularization, the main idea of which is to bring closer the outputs D for augmented and non-augmented images, also leads to leaking augmentations. The discriminator becomes "blind" to augmentations and the generator exploits it.
The authors suggest using augmentations before the discriminator always. For real and generated images. It turns out that D will never see real images. And the generator G should generate such samples, which after the augmentation will look like real images after the augmentation. You can see it well on 2(b):

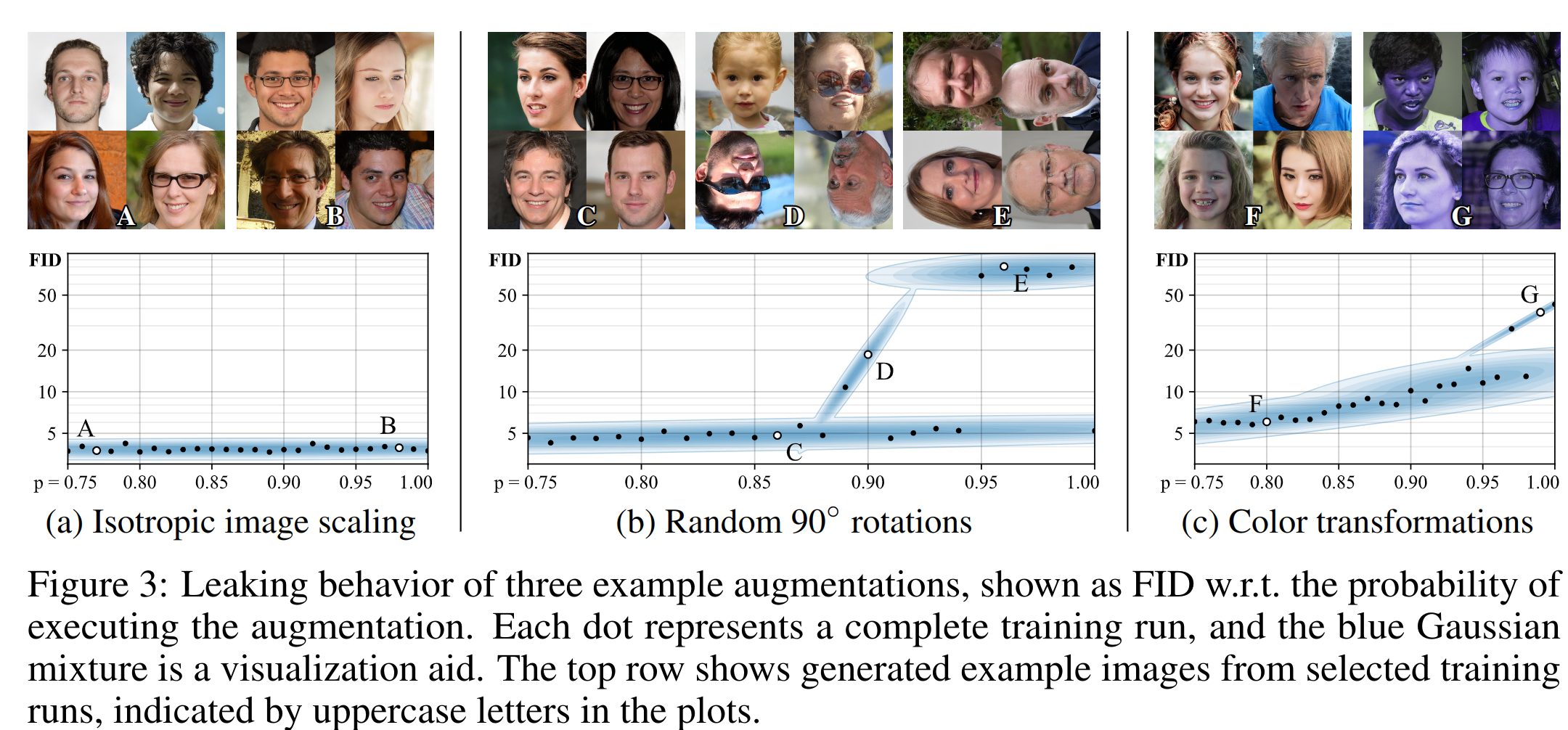
The most interesting thing is that not all augmentations are suitable, but only those that the generator can implicitly "undo". They call them "non-leaking". But this doesn't mean that each individual augmentation has to be undoable, it's more about probabilistic meaning. That is why the zeroing of 90% of the image is invertible (by applying it many times accidentally, you can guess what the original image was), and a random rotation by [0, 90, 180, 270] is not invertible (after the augmentation you can not guess the initial picture). But it becomes possible to use many different augmentations if you apply them with probability p < 1. For example, the same random rotation applied with p=0.5 will produce a picture with 0 degrees rotation more often. So you can guess which picture was before the augmentation (again, in the probability sense, not from one picture).
They tried geometric (rotations, shifts) and color transformations, additive noise, cutout, image-space filtering. It is important that since augmentations are used after G and before D in training, they must be differentiable. Usually, the composition of non-leaking augmentations is also non-leaking. They apply the augmentations sequentially in one order, each with an equal probability of value p. Even with a small p the picture after augmentations will almost always be transformed, see 2(c). Therefore, in any case, the generator should try to make pictures as default as possible, without augmentation. Whether the augmentation is leaking or not also depends on the probability of p. Examples for individual augmentations (dependence on p).
The only problem remaining is that for each dataset and amount of data, it would be necessary to find the best p. Therefore they suggested doing it adaptively, using a heuristic measure of the overfitting. Two variants of heuristic, the first uses a validation set (not very suitable), the second uses only outputs of D (proportion of positive outputs of D). 0 - not overfitting, 1 - overfitting.

Every 4 batches they update the augmentation strength p according to the selected heuristic. If heuristic shows that strong overfitting, p is increased, and vice versa. They are called it adaptive discriminator augmentation (ADA).
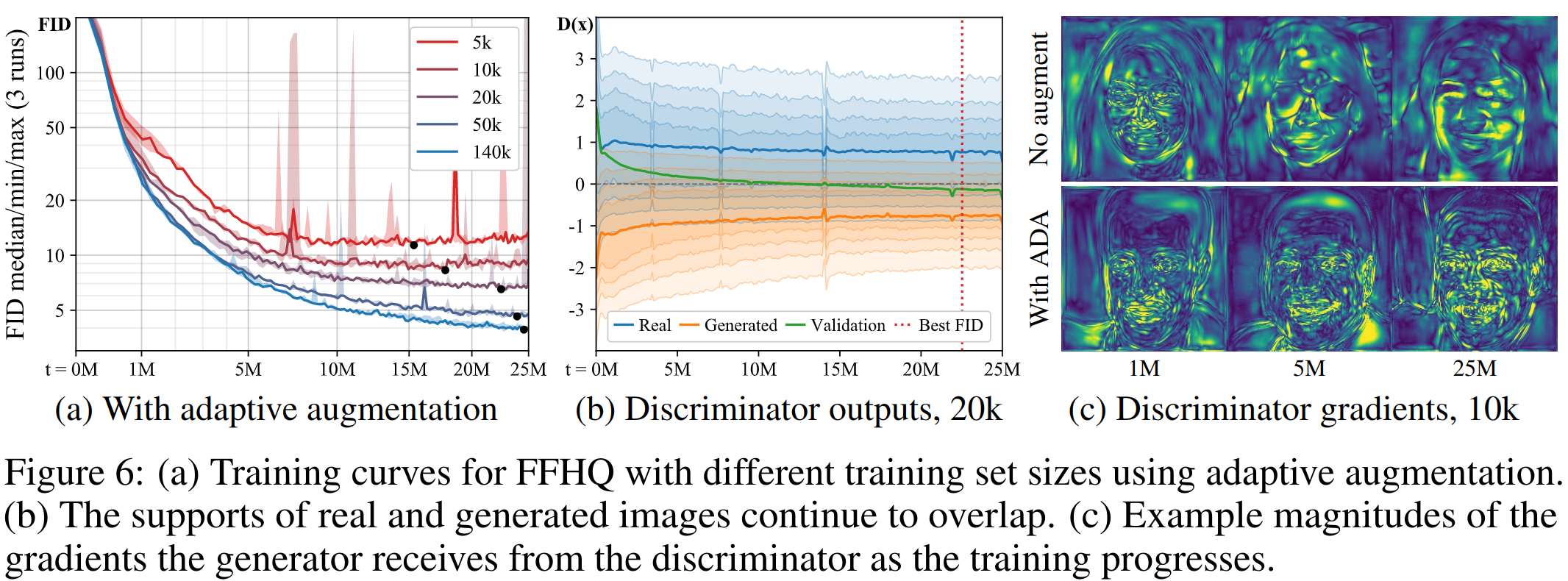
We can see that compared to figure 1, the use of ADA reduces overfitting over time, and gradients in G become sharper.
Metrics and visual results are better than those of baselines on different volumes of datasets. Their sample-efficiency allows using StyleGAN2 on new domains with only 1k images.

It also showed that it is possible to use their method for transfer learning. It significantly speeds up the learning process and makes it possible to learn something at all. They also discovered that the success of transfer learning depends primarily on the diversity of the source dataset, instead of the similarity between subjects. This is an example on their new dataset with portraits (the weights pretrained on FFHQ).

No code, but there is a pseudo code in paper for the augmentations used.