Image synthesis at CVPR 2020
This year the conference was hosted in a virtual format. It greatly reduced the number of networking for me, but allowed paying attention to more papers. Regarding the drawbacks, I listed them separately here https://twitter.com/digitman_/status/1274612391523860480
During the conference, I took notes and decided to share them. No notes were taken on the papers that I had studied in great detail earlier. That is why articles like StyleGAN2 and StarGAN2 were not included in the list. For this post to be appropriate, it will only be about image generation (well, almost).
Cross-Domain Correspondence Learning for Exemplar-Based Image Translation
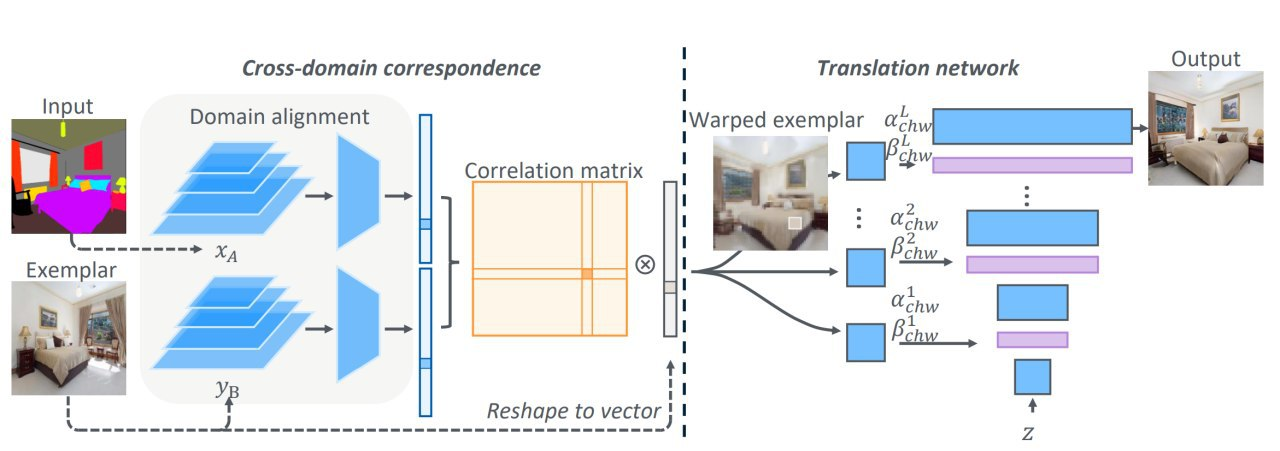
Generation of images by the segmentation mask using an example image. Style during generation is just taken from the example. In fact, it also allows you to edit arbitrary images, if there is a segmentation for them. Pipeline: by the picture of the segmentation map and picture example they extract features with different encoders into the same latent space. Then they look for how they warp in each other, warp the example, and then further improve with the generator, which takes warped features through AdaIN. Results https://youtu.be/RkHnQYn9gR0
SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
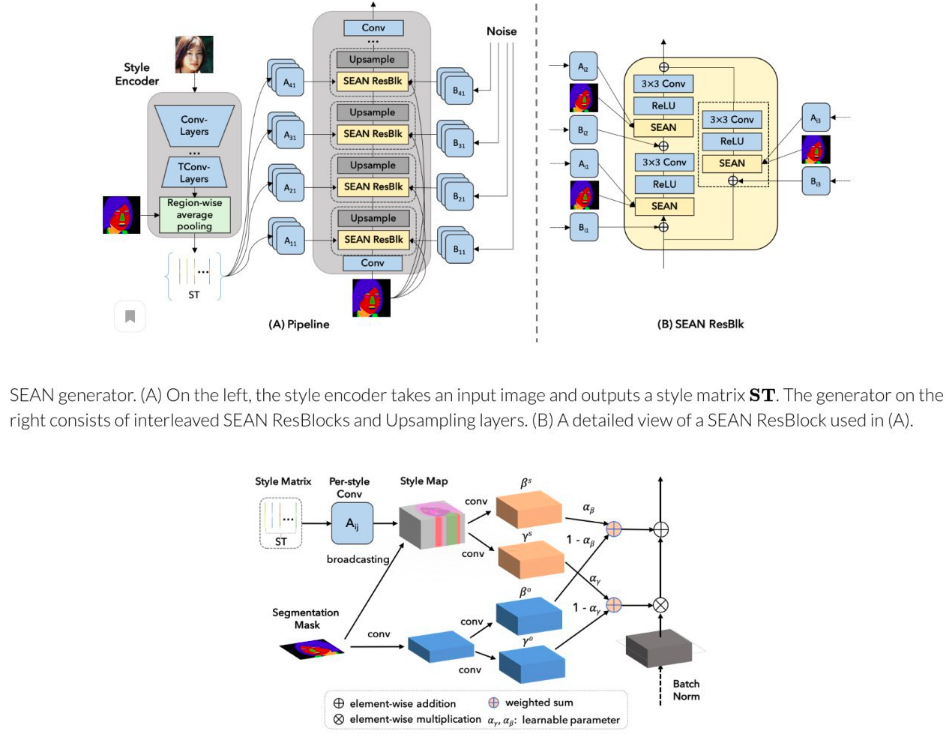
Although SPADE generates a good picture by the segmentation mask, it is not enough for the authors. They add to SPADE a normalization block in addition to the segmentation map also information about style. And the style is encoded for each region of the image with a separate encoder. In this way you can make a style mixing by changing the styles of different parts of the face. Results https://youtu.be/0Vbj9xFgoUw
SegAttnGAN: Text to Image Generation with Segmentation Attention
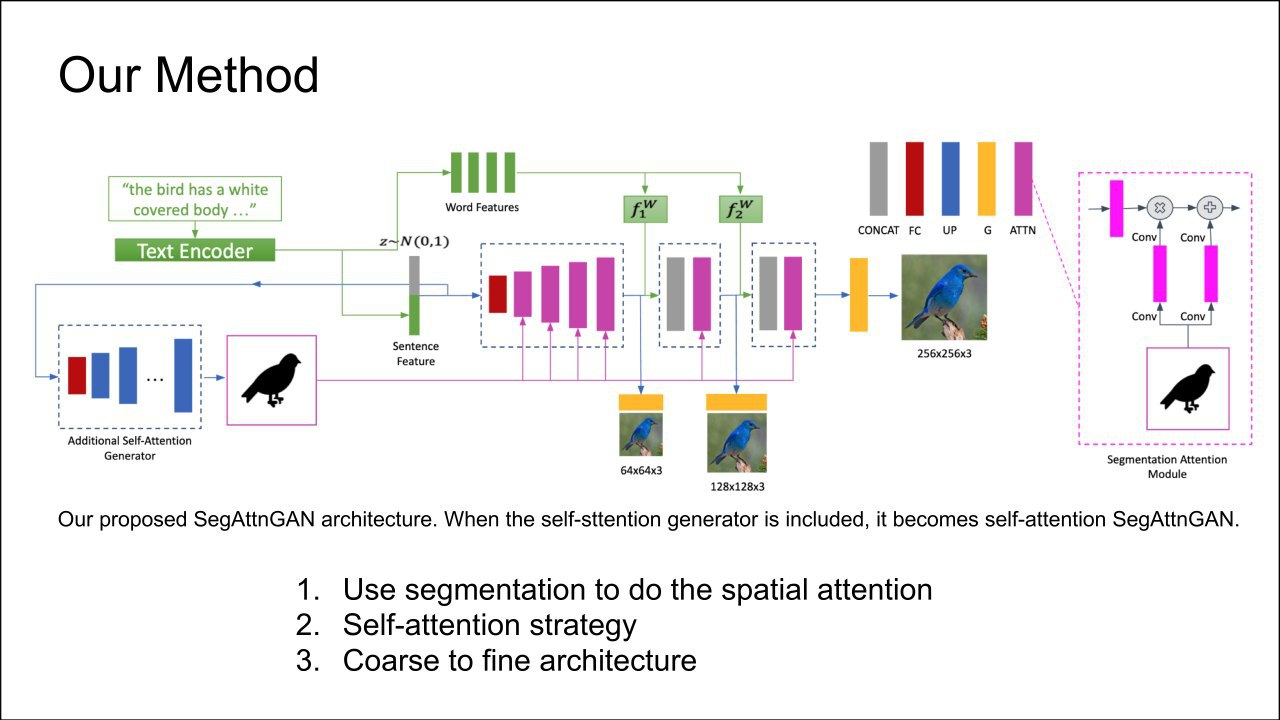
AttnGAN improvement - a network that generates an image from the text (in a narrow domain). Text encoder takes features for sentences and separate words, and previously from it was just a multi-scale generator. Now a segmentation mask is generated from the same embedding using self attention. The mask is fed to the generator via SPADE blocks.
FaR-GAN for One-Shot Face Reenactment
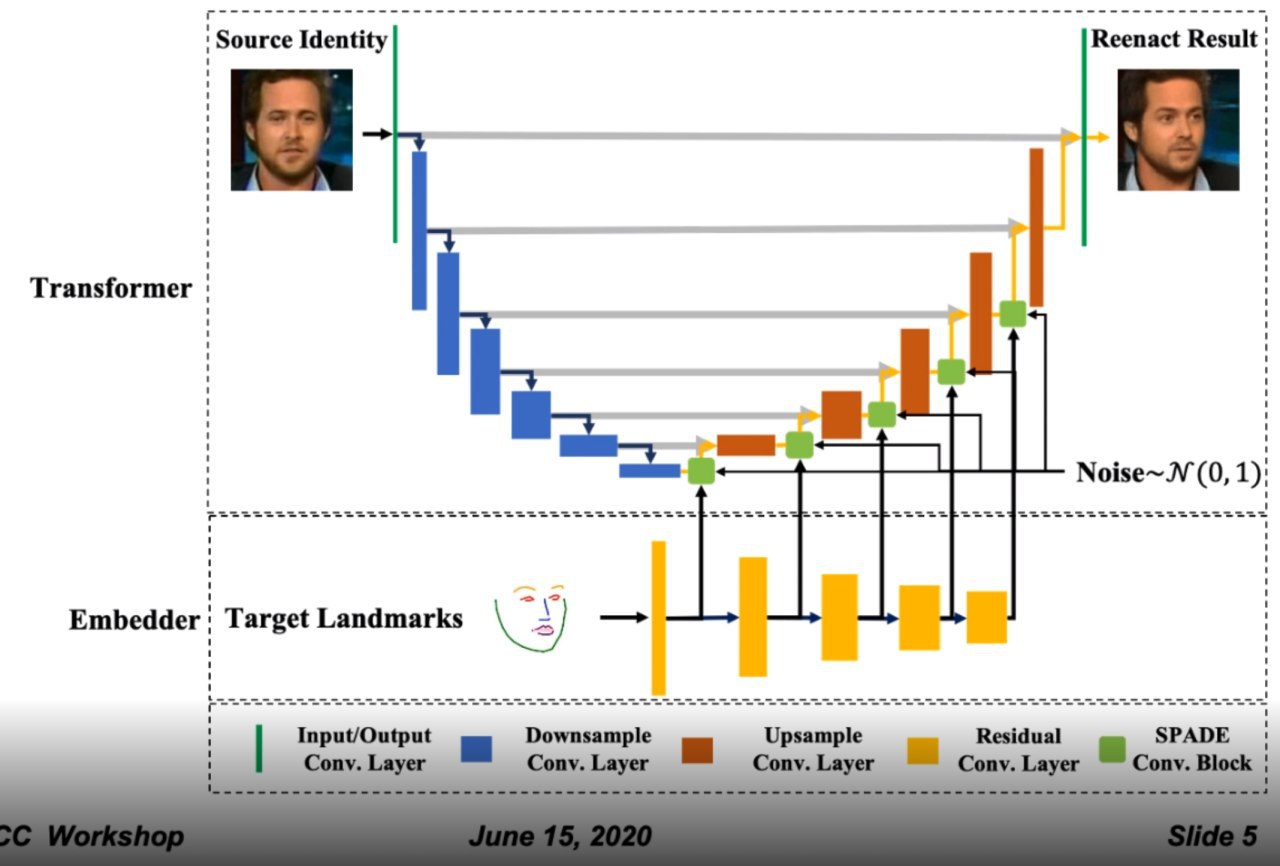
Manipulation for faces by one photo. SPADE generator, starts with the bottleneck from the encoder (which takes the original photo), SPADE blocks take the view of a new "face pose". Also, noise is added.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
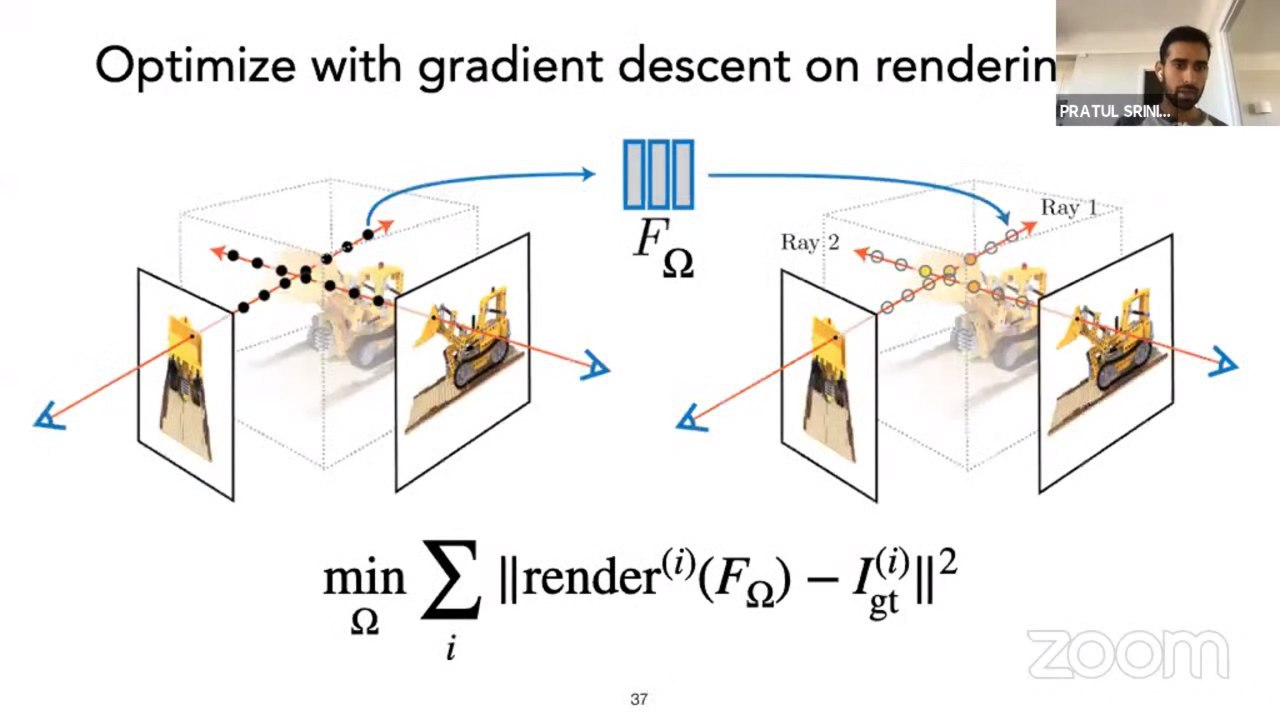
They fit for each scene a separate model (~30sec), which by coordinates in the scene and the direction generates a view, which then goes into the render. It takes a bunch of pictures of the scene. It is trained through differentiated rendering. This work allows you to generate video of the flights in the scene, change the lighting, etc. Results https://www.matthewtancik.com/nerf
Learning to Simulate Dynamic Environments with GameGAN
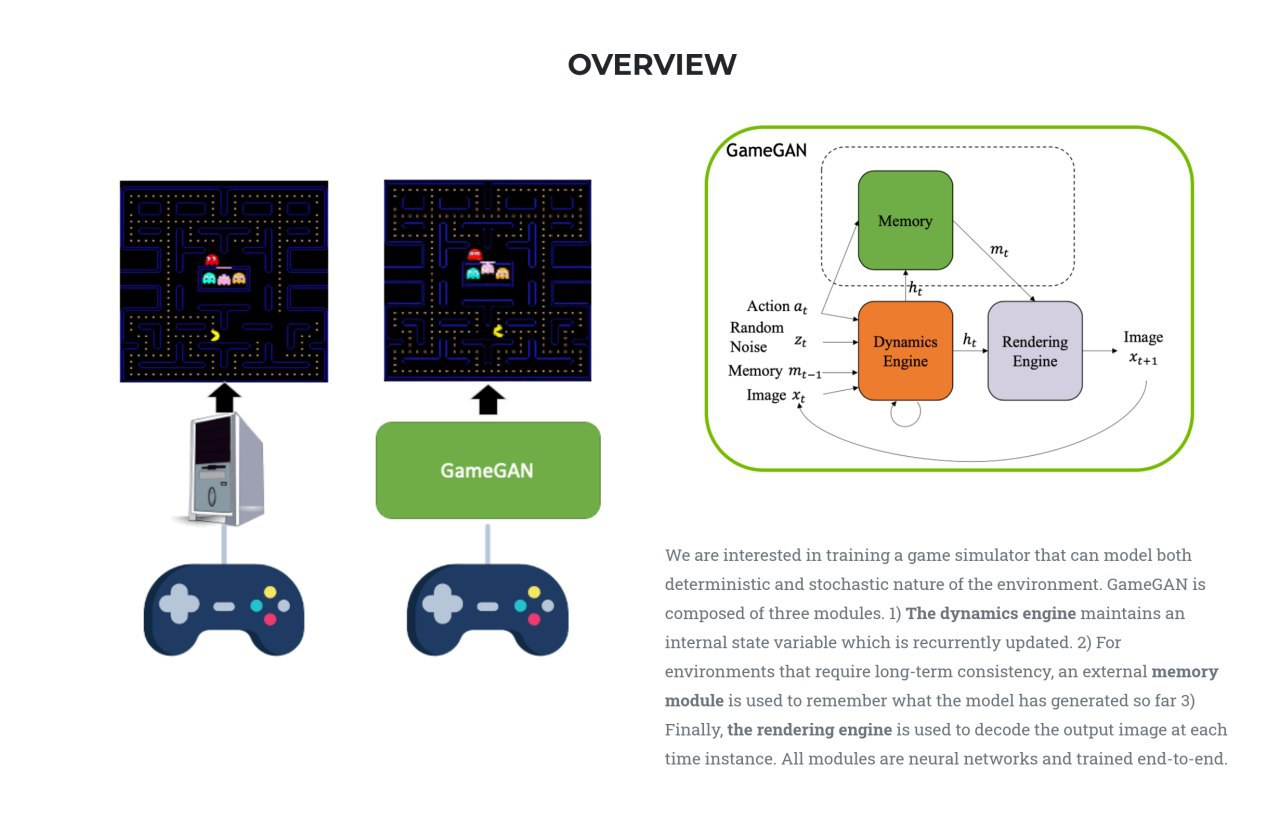
Simulation of simple 2d games using the prediction of the next frame. World Model re-invention (which Schmidhuber made originally). Funny trick - you can change the background. Results https://youtu.be/4OzJUNsPx60
Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
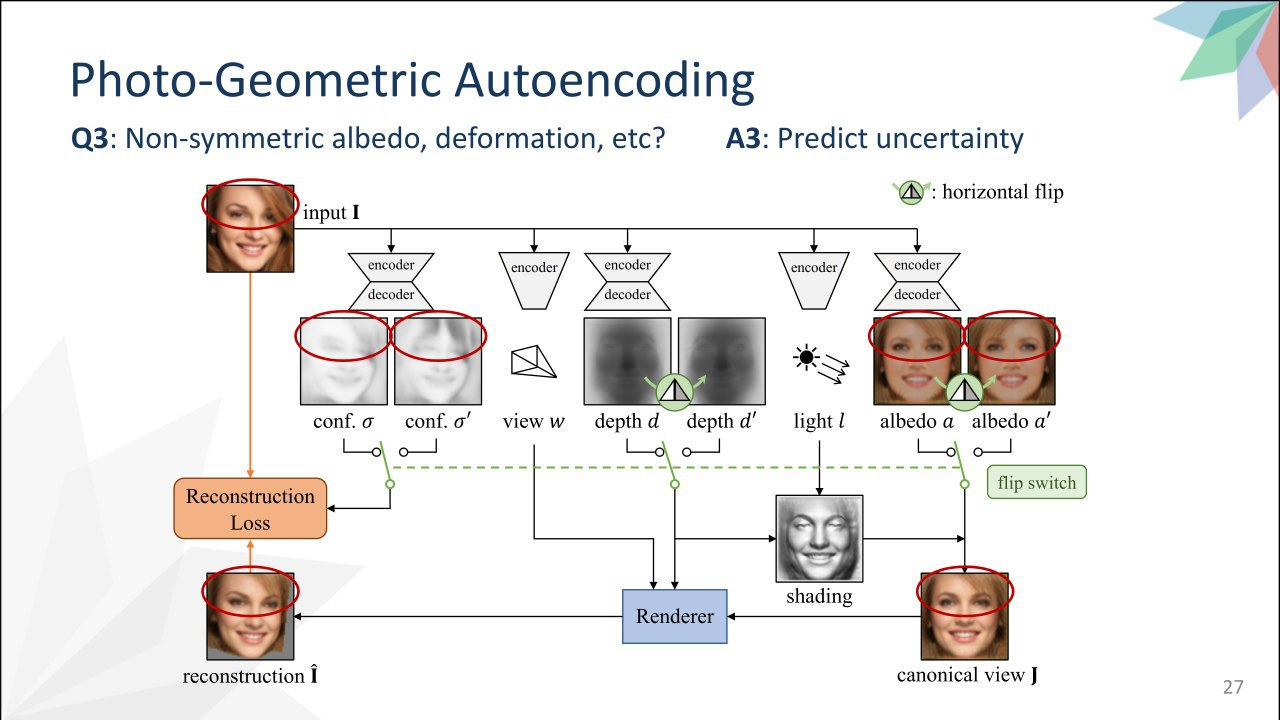
Winner of the "best paper". Allows you to get a 3d model with one photo without any additional labels. But works only for symmetrical objects, what are the faces (well, almost). Predict by photo uncertainty maps, depth, texture, view point and light. Serve all in a differentiated rendering (17th year). Loss - restoration of the original photo. But it just did not work - not enough "defined" task. That's why they used symmetry - they flip textures, confidential maps and shadows to make it works that way too. By the link, you can try with your photo http://www.robots.ox.ac.uk/~vgg/blog/unsupervised-learning-of-probably-symmetric-deformable-3d-objects-from-images-in-the-wild.html
Advancing High Fidelity Identity Swapping for Forgery Detection
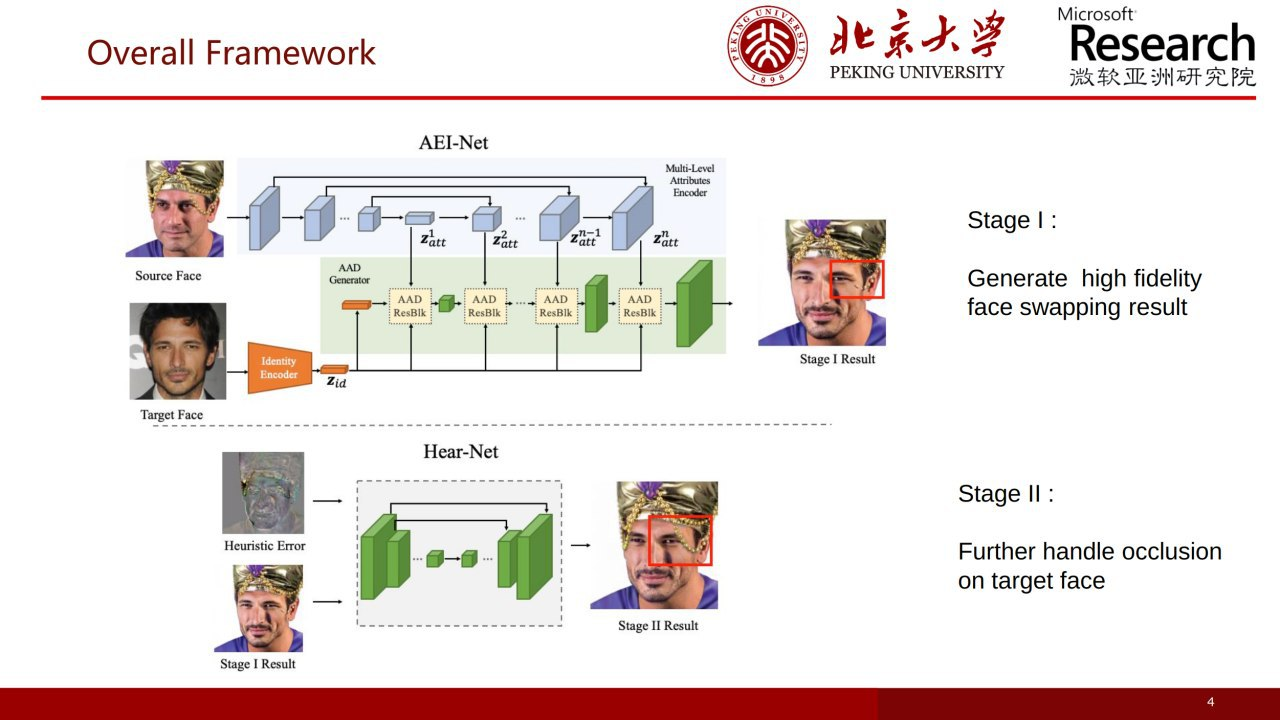
One shot face-swap, using SPADE to throw a facial geometry of a source, and AdaIN to throw a face identity of a target. The result is enhanced by a second model, which takes the result of the previous step and the difference between this result and the source - this allows to return missing parts or objects on the face. Results https://youtu.be/qNvpNuqfNZs
Disentangled Image Generation Through Structured Noise Injection
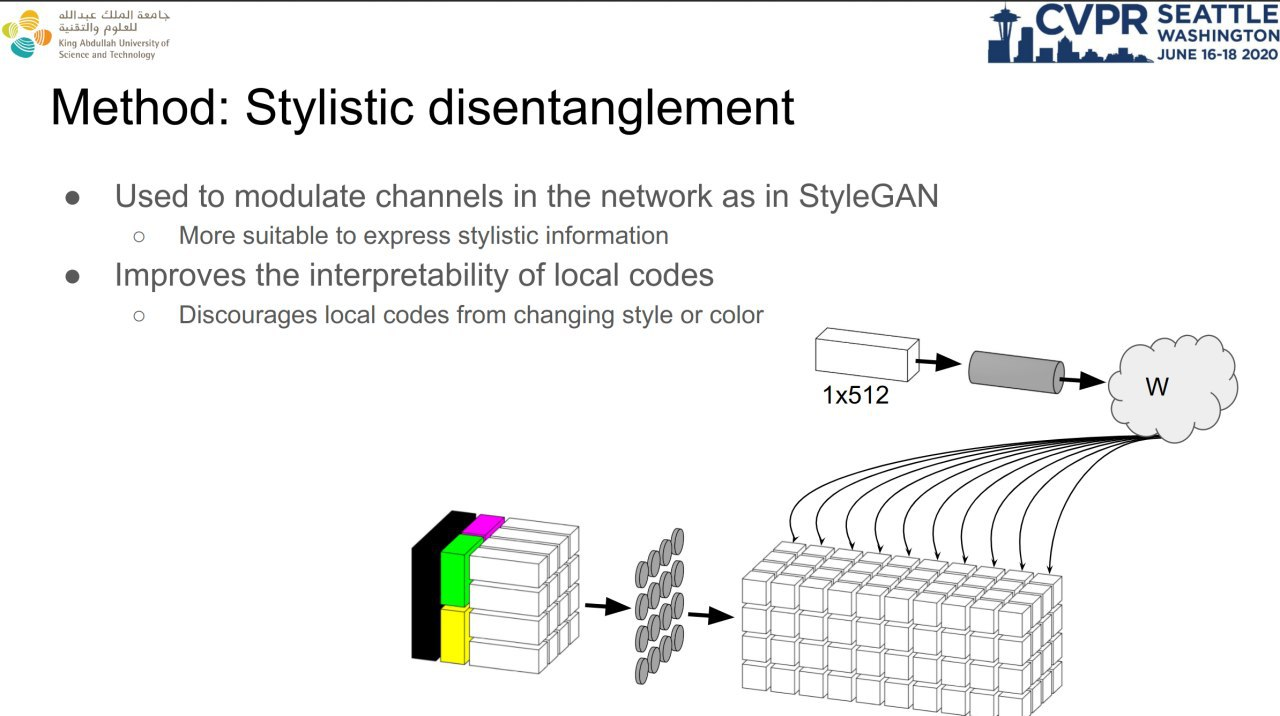
The authors like how StyleGAN can generate different faces, but don't like that you can't manipulate the local part of the image with latent code (which is global). So they suggest changing the default StyleGAN slightly. Instead of a 4x4x512 constant input tensor, a tensor is supplied which is divided into 4 logical parts through channels. The global code is one in the spatial part (1x1 is stretched to 4x4). Shared 2x2(stretched to 4x4), local 4x4. AdaIN in the generator also remains, each code is generated separately. This allows to change the local parts of the face without affecting the global ones. Results https://youtu.be/7h-7wso9E0k
Cascade EF-GAN: Progressive Facial Expression Editing With Local Focuses
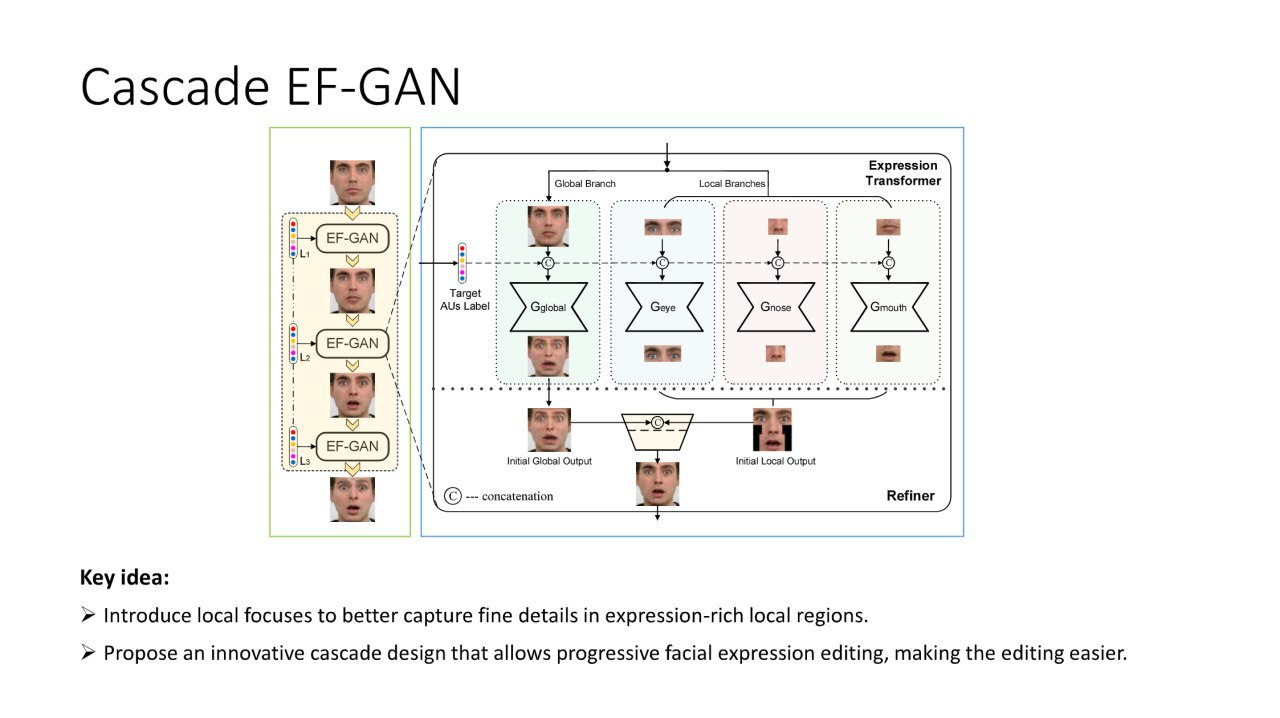
A net for changing facial expressions. Added 2 modifications to image2image. Individually change the eyes, nose, mouth locally, and then connect everything. Progressive editing - runs the result through the net several times.
PSGAN: Pose and Expression Robust Spatial-Aware GAN for Customizable Makeup Transfer
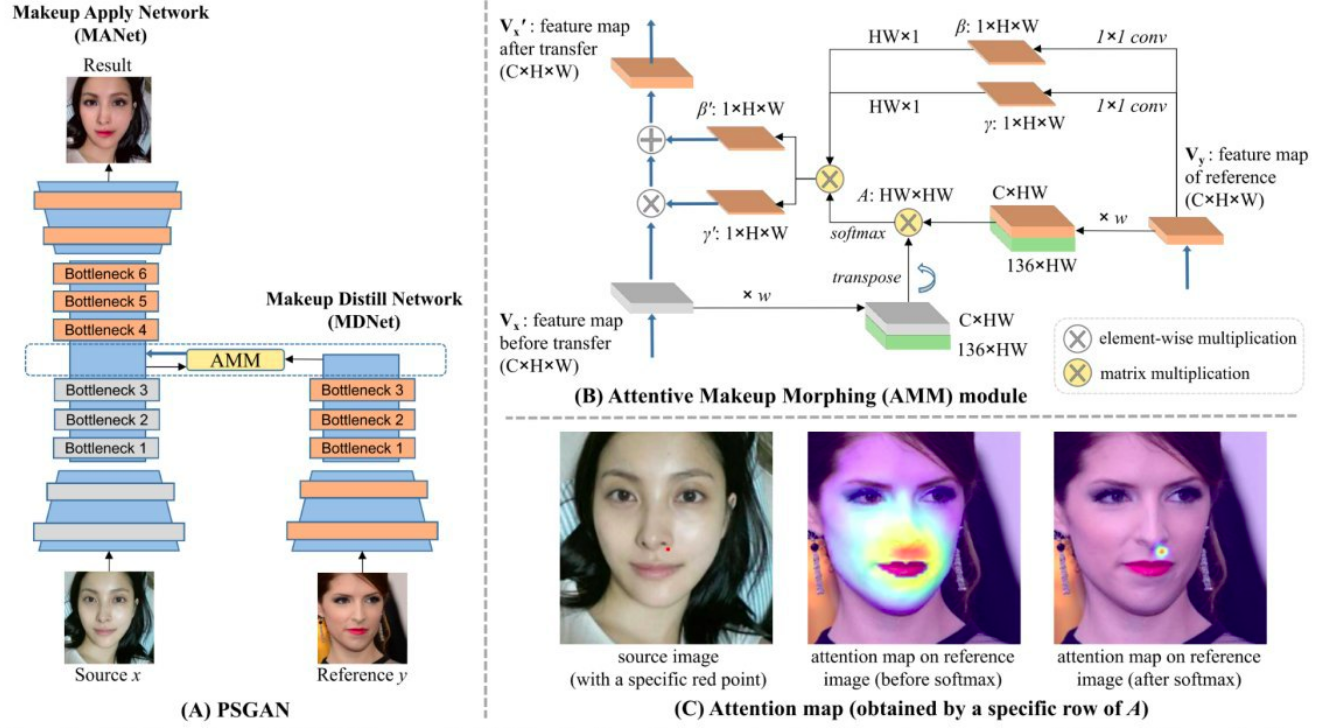
Make-up transfer, solved the problems of previous approaches (they did not work if there is a big difference in pose or lighting) with the help of an attention. The attention between the source image's bottleneck and the image reference's bottleneck. Many losses were also used, in addition to the adversarial.
MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation
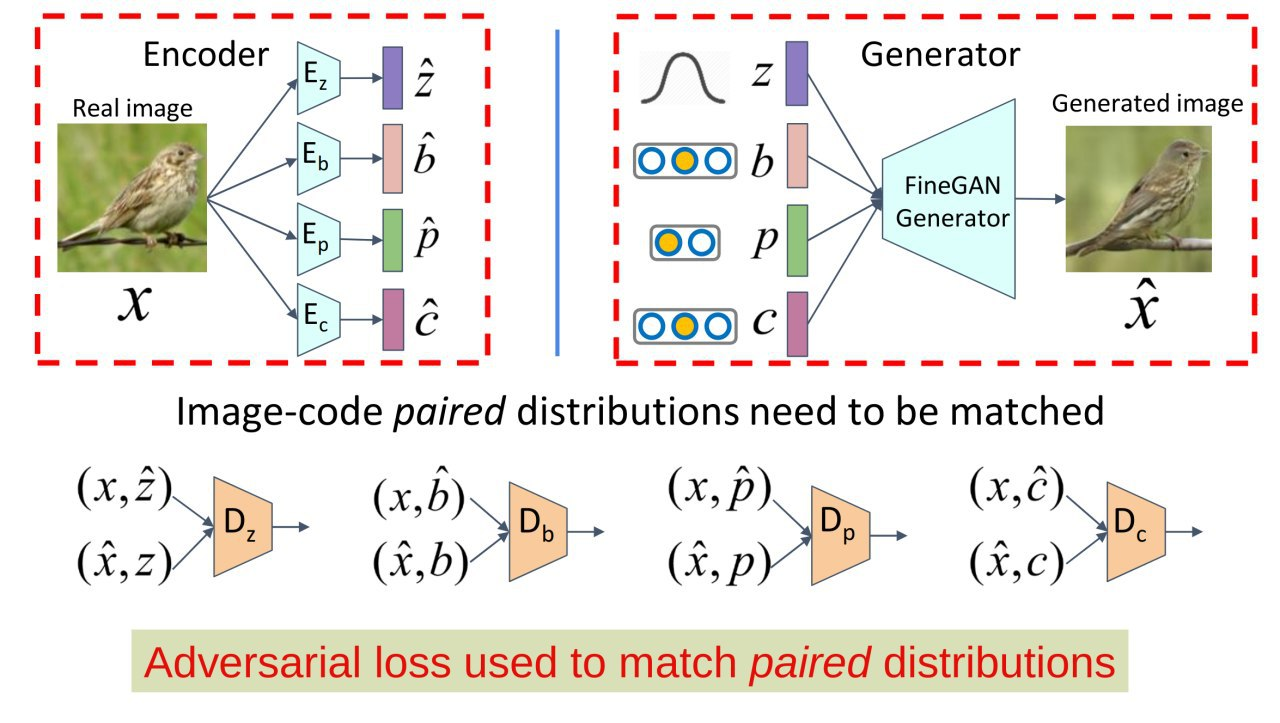
Allows you to generate a picture in parts, dividing it into background, shape, texture and pose. There is a different encoder for each entity.
Learning to Shadow Hand-Drawn Sketches
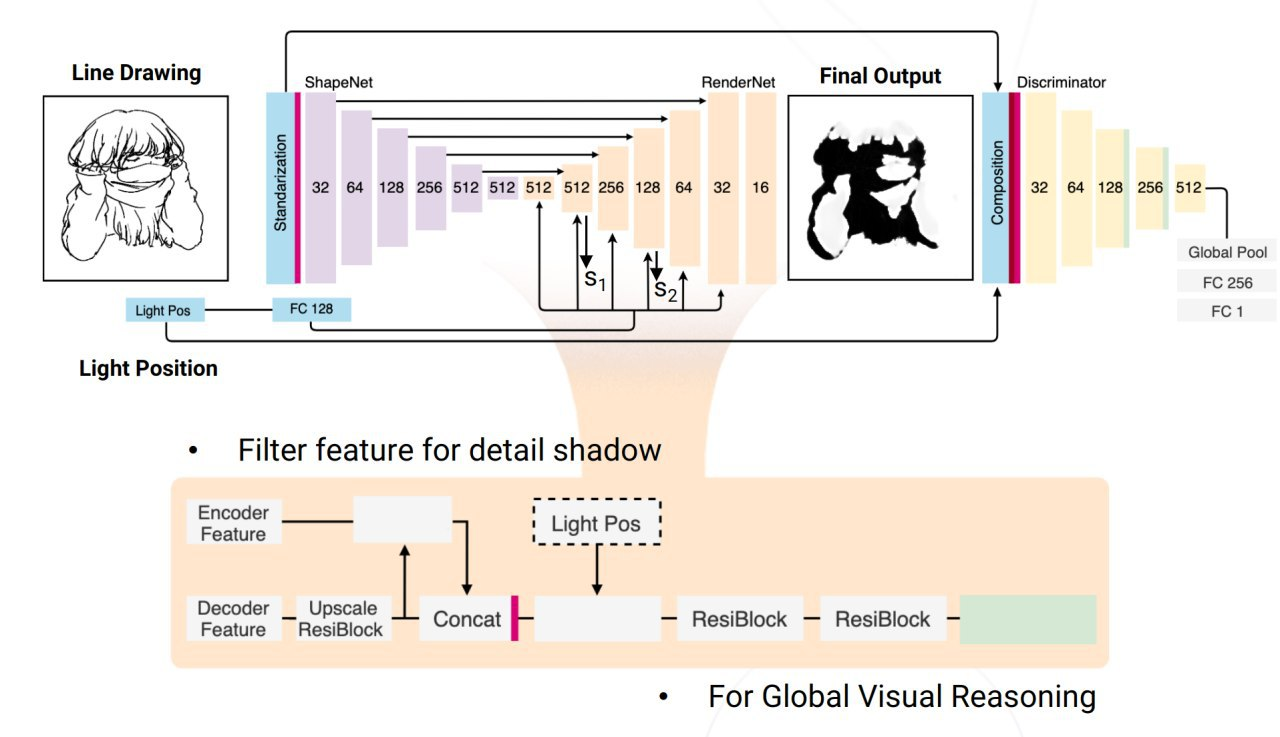
Adding shadows to sketches. They collect a small dataset (1k) of sketch examples and shadows for them. They hard-coded 26 different positions of the light. Train image2image to predict the mask of the shadow.
Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation
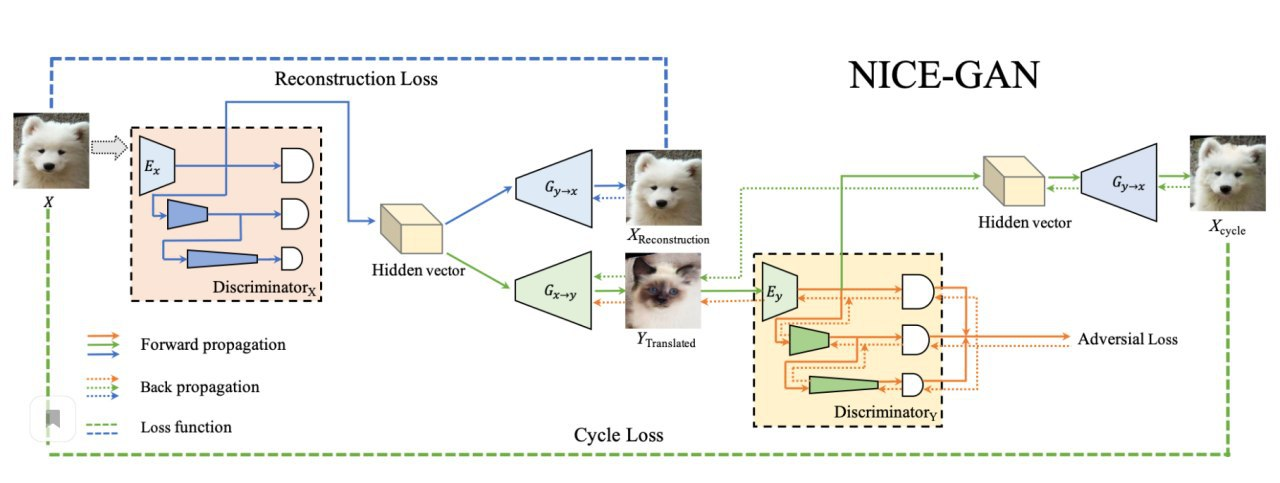
An improvement of image2image translation for unpaired data. It was suggested to reuse part of the encoder in the discriminator.
Unpaired Portrait Drawing Generation via Asymmetric Cycle Mapping
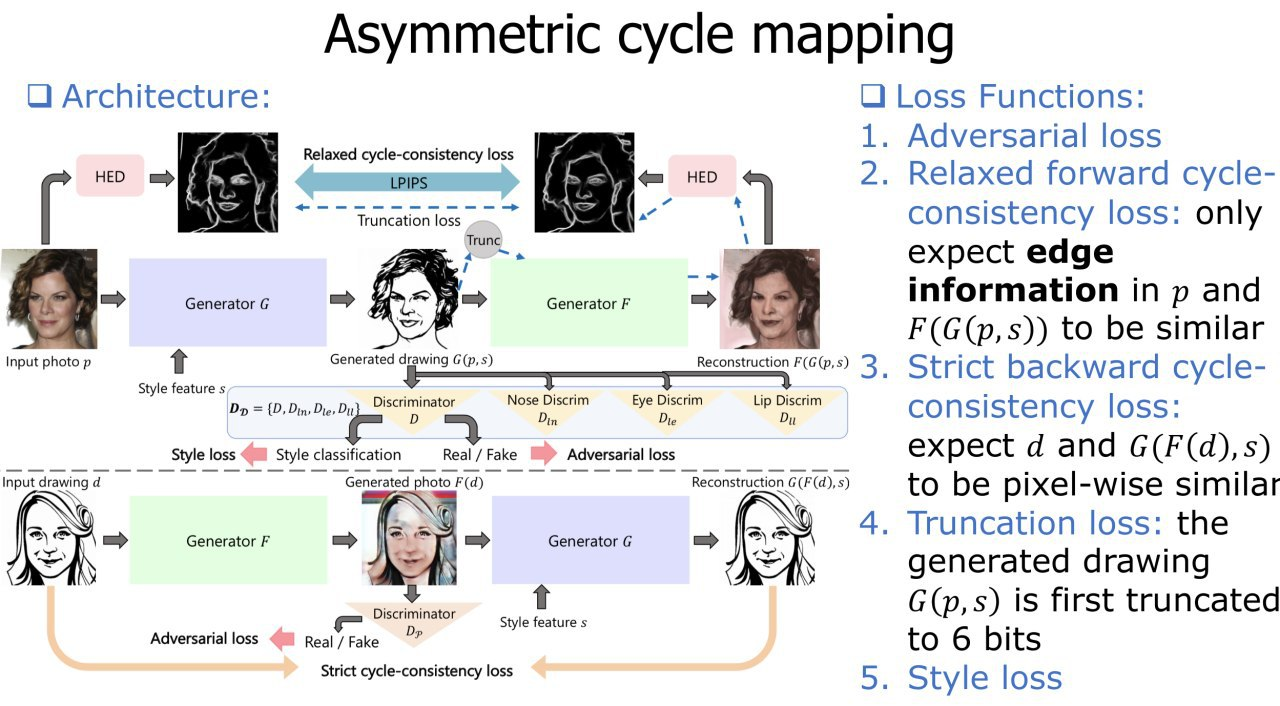
Makes an unpaired image2image transfer of the face in the painted face. Fix the weaknesses of previous methods. The main feature is that the forward cycle consistency is not as strict as backward, which allows during the generation of a drawn face to do this for the generator more freely.
SketchyCOCO: Image Generation From Freehand Scene Sketches

There are works that turn segmentation, text, bounding boxes or even individual sketches into a picture. But there was no whole sketch by hand in the picture - now there is. They are generated in two phases - first the objects in the foreground (trying to maximize accuracy). Then the background - it can be generated more freely (not too much of a match with the input painted tree or cloud). Made their own dataset of pictures in the sketch: animals are replaced by the nearest similar in the dataset of painted animals, and the background is approximately. The results are pretty cool.
BachGAN: High-Resolution Image Synthesis From Salient Object Layout
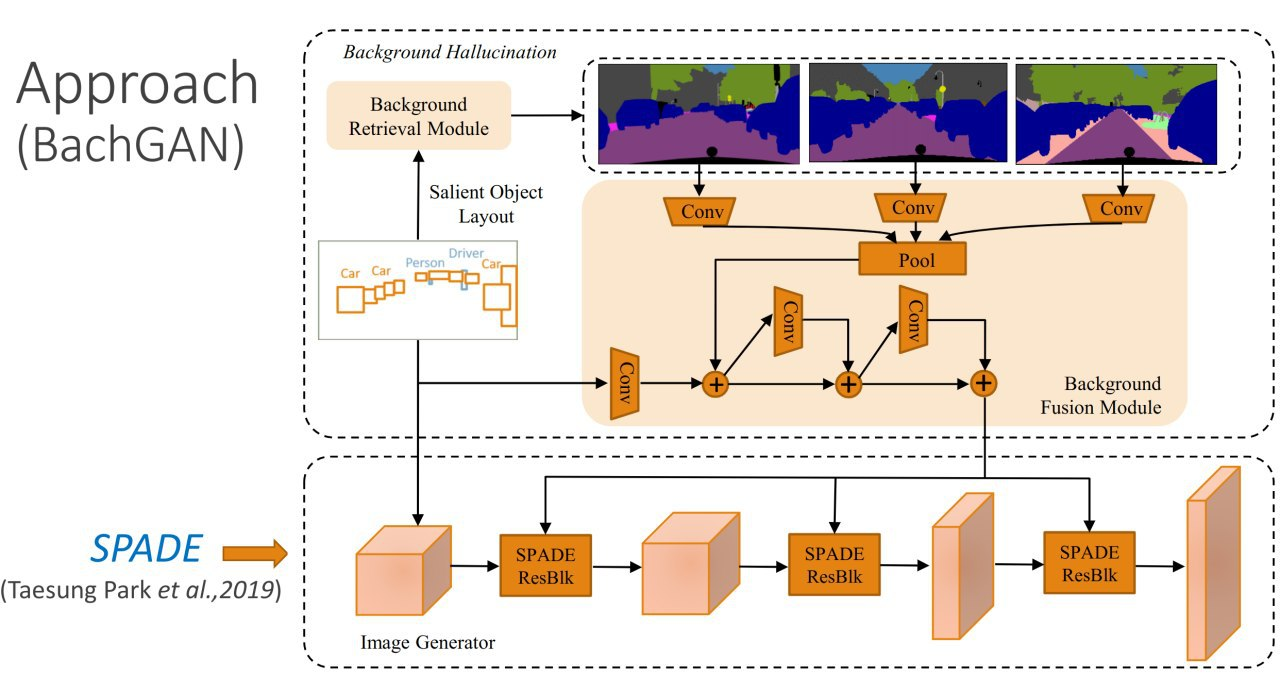
Now image2image is already quite well generated from image segmentation. But a complete semantic map is not always there, it is much easier to get the bundling boxes with labels. But it is more difficult to generate from such labels, so the authors offer to "help" the generator by adding to the generator info about similar backgrounds from the dataset with full segmentation labels.
Neural Rerendering in the Wild
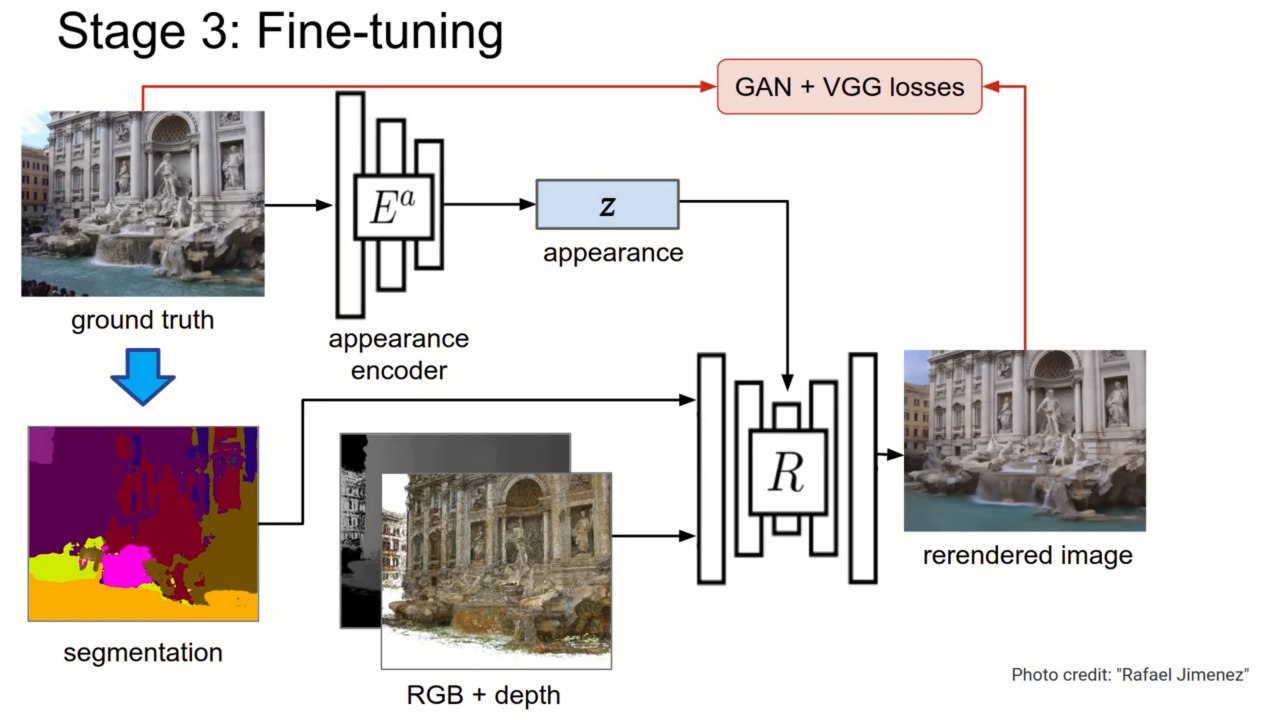
Last year's work was on the tutorial this year. On a bunch of photos of attractions they receive a 3d point cloud by classical methods. Then they train image2image model to restore the original photo of the landmark by its presentation in the point cloud. You can get normal results, but blurred crowds of tourists, as well as different environmental conditions (weather, time of day). It is fixed with separate encoder for the appearance, which encodes the environmental conditions, and using semantic segmentation. On the inference you can fix the time of day and weather, as well as remove people. Results https://youtu.be/E1crWQn_kmY
Attentive Normalization for Conditional Image Generation
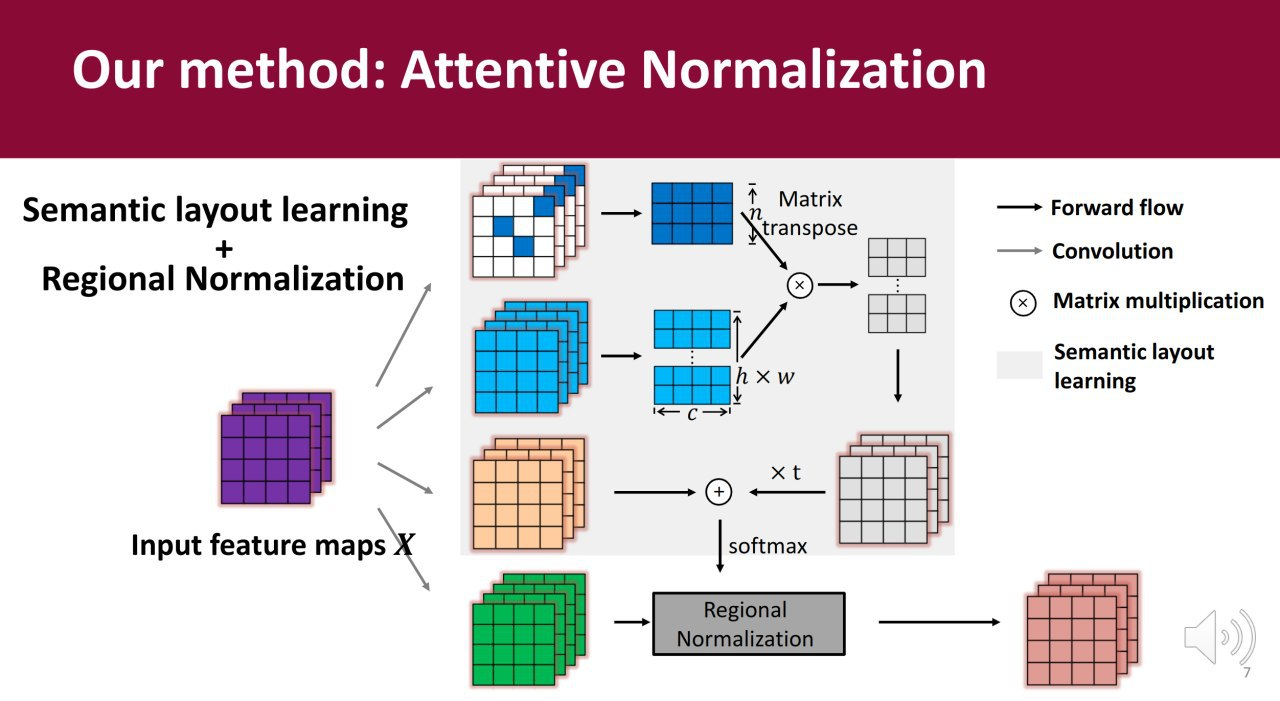
The attention in the GANs works pretty good. As originally shown in SA-GAN (Self-Attention GAN). But it's a quadratic complexity in the spatial size of the feature map, the authors made their crutch to make the complexity linear. They also have an interpretation of what a semantic scene map should be learned inside it. The results and speed beat the baselines.
Freeze the Discriminator: a Simple Baseline for Fine-Tuning GANs
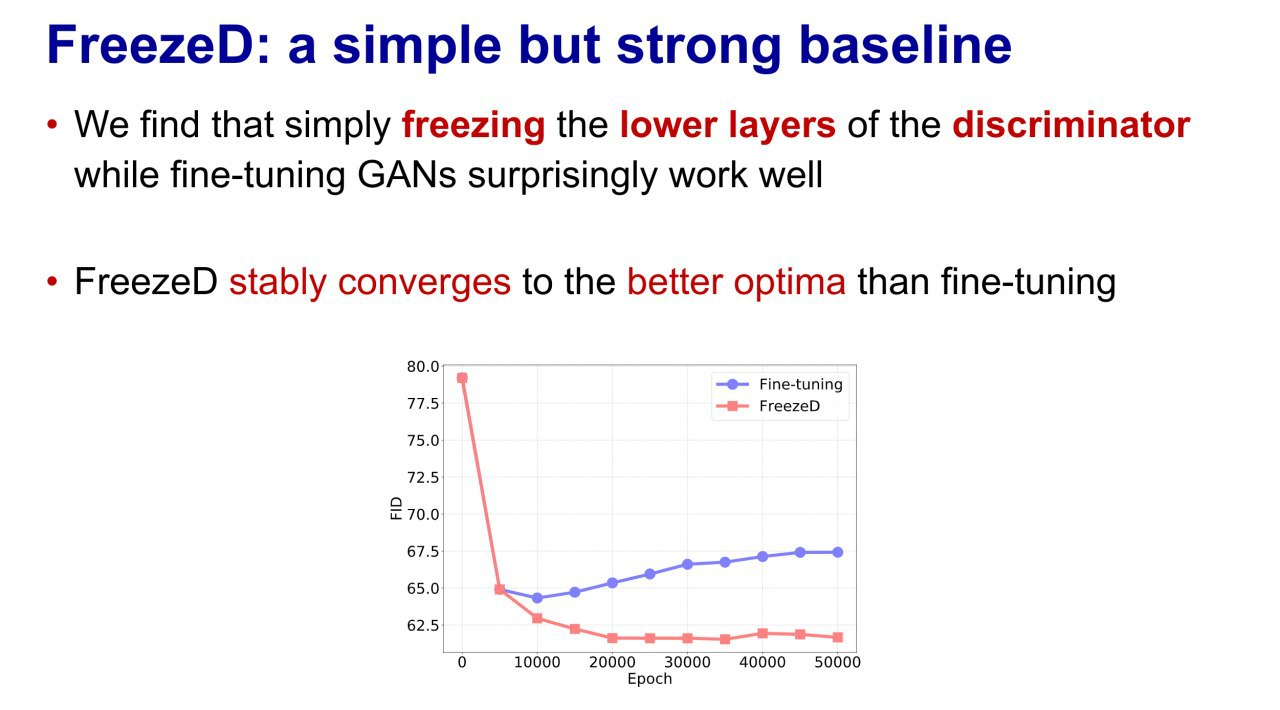
Simple freezing of the first few layers of the discriminator is better than fine-tuning in its entirety.