Deep Image Spatial Transformation for Person Image Generation
https://arxiv.org/abs/2003.00696

Work on conditional generation of bodies. To generate a person in a new pose, a global warping of features is used, and to clarify it a local attention is used. By gifs on the Github we can see that it works stably even for video, though it generates one frame each independently.
First of all, they discuss the applicability of CNN, when the source and target objects do not match in space - one of the solutions is to move-rotate features, such as in the Spatial Transformer Network. But for bodies it should not be done globally, but locally. For working with local parts in different areas of deep learning attention has proved to be a good. In this work, it is necessary to match the same parts of the object on different images.
Their pipeline consists of two models Global Flow Field Estimator F and Local Neural Texture Renderer G. F generates an optical stream between the two images w and the mask m. w and m go to the local attention block of the G network, where the warping of the original features and the generation of a new image takes place.

F takes the original picture, the original pose and the target pose, and at the output predicts the optical flow from the original image to the target and mask. The mask has values between 0 and 1 and indicates whether the original features can be used in the new position or whether it should be generated by context. The optical flow learns unsupervised and two regularizers put on it to make it fit. Sampling correctness loss - measures the similarity of the original VGG features and VGG of the target image. The second regularizer penalizes if in the local neighborhood the transformation is not similar to the Affine transformation (which is optimal in this area between the original and target image).
The second G network generates a person in the target image position. It receives the source image, the target pose and the optical stream with the mask obtained above. For the source image, the encoder generates f_s features, while for the target position, a separate encoder generates f_t features.

The source features f_s and target f_t are then fed into the Local Attention block. They move f_t in width and height and take local patches of nxn size (5x5 or 3x3) and corresponding patches in f_s. But to match objects on the source and target feature mapps, the patch from f_s is taken with an offset, which is an optical flow (because the coordinates may not be integer, it uses bilinear sampling). Two patches concatenate and feed into the kernel prediction network M with softmax at the end, which predicts the kernel for convolution - in fact, local attention for the patch size nxn. They apply a convolution with this kernel on the source patch from f_s with offset and average pull - so for each local patch. They get a new feature map f_attn. They also showed that gradients flow better through this pipeline than through simple warping without attention.
But not for every point in the new position there is a match in the initial position, so some regions need to be generated from scratch. Which regions to generate is exactly what the mask m shows.
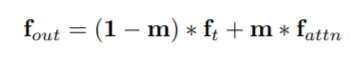
The decoder that generates the image is starting from f_out. Losses - l1, perceptual, style and adversarial are put between the generated image and the target.
On the Market-1501 and DeepFashion datasets they better than baselines.

On DeepFashion of 256x256 resolution they used two attention blocks, on 32x32 with n=3 and on 64x64 with n=5. At first they trained the Flow Field Estimator, and then continue end2end.
Works for other domains as well.
